ETRI,
절차 생성 AI 벤치마크 기술 세계 최초 개발
ETRI가 대형언어모델(LLM)* 기반으로 제작된 절차 성능을 자동 평가하는 로타벤치마크(LoTa-Bench) 기술을 세계 최초로 개발했다. 이로써 빠르고 객관적인 절차 생성 성능 평가가 가능해질 것으로 기대된다.
* 수많은 파라미터를 보유한 인공 신경망으로 구성되는 언어 모델

세계 최초 절차 생성 AI 성능 평가 기술 개발
“전자레인지에 차갑게 식힌 사과를 넣어라.”라고 명령하면 로봇은 어떻게 반응할까?
먼저 사과를 찾고, 사과를 집어 들고, 냉장고를 찾아 냉장고 문을 열고, 사과를 내려놓아야 할 것이다. 이후 냉장고 문을 닫고, 다시 냉장고 문을 열어 차갑게 식힌 사과를 찾아 사과를 집어 들고, 냉장고 문을 닫는다. 이후 전자레인지를 찾아 문을 열고, 사과를 넣어 전자레인지 문을 닫아야 할 것이다. 이러한 사례의 절차를 얼마나 잘 수행했는지 평가하는 것이 바로 절차 생성 AI 벤치마크 기술이다. 로봇이 명령에 얼마나 잘 대응하고 절차를 준수했는지 성능을 보는 것이다.
ETRI가 사람이 말로 작업을 명령하면 스스로 작업 절차를 이해하고 계획을 수립해 수행하는 절차 생성 인공지능(AI)의 성능을 자동 평가할 수 있는 로타벤치마크(LoTa-Bench)* 기술을 개발했다. 알프레드(ALFRED) 기반 벤치마크 결과, 오픈AI(OpenAI)의 GPT-3는 21.36%, GPT-4는 40.38%, 메타(Meta)의 라마2(LLaMA 2)-70B 모델이 18.27%, 모자이크엠엘(MosaicML)의 MPT-30B 모델이 18.75% 성공률을 보였다고 밝혔다. 규모가 클수록 절차 생성 능력도 우수했다. 성공률이 20%면 100개의 절차 중 20개를 성공한 셈이다.
* LoTa-Bench: ETRI가 개발한 절차 생성 인공지능 벤치마크 기술. Language-oriented Task Planning의 약자.
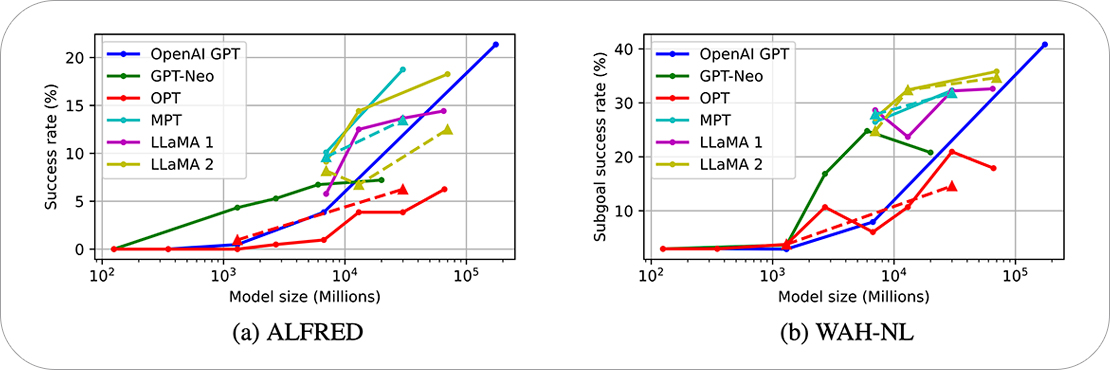
다양한 대형언어모델의 절차 생성 성능 평가 결과
연구진은 세계 최우수 인공지능 학술대회 중 하나인 표현학습국제학회(ICLR)*에 논문을 발표했다. 또한 본 기술을 이용해 대형언어모델 총 33종의 절차 생성 성능 평가 결과를 깃허브에 공개했다.
* ICLR(International Conference on Learning Representations): https://openreview.net/forum?id=ADSxCpCu9s
효율과 객관성을 자랑하는 로타벤치마크 기술
기존에는 절차 이해 성능 평가를 자동으로 할 수 있는 벤치마크* 기술이 없었다. 그래서 사람이 직접 평가해 손이 많이 갈 수밖에 없었다. 일례로 구글의 세이캔(SayCan)**을 비롯한 기존 연구에서는 여러 사람이 직접 작업 수행 결과를 관찰하고 성공과 실패 여부를 투표하는 방법을 사용했다. 하지만 이런 방법은 성능 평가에 긴 시간과 노력이 들어 번거로울 뿐 아니라, 평가 결과에 주관적 판단이 개입된다는 단점이 있었다.
ETRI가 개발한 로타벤치마크 기술은 사용자의 명령에 따라 대형언어모델이 생성한 작업 절차를 실행하고, 결과가 지시한 목표와 같은지 자동으로 비교하여 성공 여부를 판단한다. 그래서 평가 시간과 비용을 최소화할 수 있고, 객관적인 결과를 얻을 수 있다.
* 벤치마크(Benchmark): 컴퓨터 부품 등의 성능을 비교, 평가하여 점수를 내는 시스템
** https://say-can.github.io/

“Put a chilled apple in the microwave.”라는 명령에 따른 절차 생성 사례
성능 평가는 로봇과 체화 에이전트 지능의 연구개발 목적으로 개발된 미국 알렌인공지능연구소(AI2-THOR*)와 미국 MIT(버츄얼홈, VirtualHome**) 가상 시뮬레이션 환경에서 이뤄졌다. “전자레인지에 차갑게 식힌 사과를 넣어라.”라는 일상적인 가사 작업 지시 명령을 내리고, 각 작업 절차를 포함하는 데이터셋***으로 평가했다. 연구진은 본 기술을 기업, 학교 등에서 자유롭게 활용하도록 소프트웨어****를 오픈소스로 공개했다.
* AI2-THOR: 로봇 홈 서비스 시뮬레이터
** Virtualhome: 프로그램을 통한 가사활동 시뮬레이션
*** Alfred: 일상 가사 작업 수행 성능을 시험 평가하는 벤치마크
Watch-and-help: 사람의 작업 의도를 인식하여 협업하는 인공지능의 성능을 시험 평가하는 벤치마크
**** https://github.com/lbaa2022/LLMTaskPlanning
로봇 지능의 고도화를 위한 지속적인 연구
연구진은 로타벤치마크 기술의 이점을 다방면으로 활용했다. 그 결과 데이터를 통한 훈련으로 절차 생성 성능을 개선할 수 있는 두 가지 전략을 발견했다. 컨텍스트 내 예제 선별법(In-Context Example Selection)*과 피드백 기반 재계획(Feedback and Replanning)**이다. 아울러 파인튜닝을 통한 절차 생성 성능 개선 효과도 확인했다.
ETRI 장민수 소셜로보틱스연구실 책임연구원은 “로타벤치마크는 절차 생성 AI 개발의 첫걸음이다. 향후 불확실한 상황에서 작업 실패를 예측하거나 사람에게 질문하며 도움을 받아 작업 생성 지능을 지속 개선하는 기술을 연구개발 할 계획이다. 1 가구 1 로봇 생활 시대의 구현을 위해서는 본 기술이 반드시 필요하다”라고 말했다.
ETRI 김재홍 소셜로보틱스연구실장은 “ETRI는 실세계에서 각종 임무 계획을 생성하고 실행할 수 있는 로봇을 실현하기 위해 파운데이션 모델을 활용한 로봇 지능 고도화 연구개발에 매진하고 있다”라고 밝혔다.
* 컨텍스트 내 예제 선별법(In-Context Example Selection): 사용자가 내린 명령과 유사한 절차 생성 예제를 선별하여 프롬프트에 적용하는 전략이다.
** 피드백 기반 재계획(Feedback and Replanning): 생성된 절차 실행에 실패하면 실패 원인을 분석해 대형언어모델에 피드백으로 제공하고 계획을 재생성하는 방식이다. 예컨대, 사과를 집어야 하는데 사과가 없어 실패하였을 때 다시 한번 사과를 찾을 수 있도록 계획을 재생성해 성공률을 높이는 것이다.

 이전 기사보기
이전 기사보기



